- A+
一、为什么要导出 50000 条海量关键词?
导出 50000 条甚至更多的关键词,绝非追求数量上的满足感,而是为了获得一个完整、多维度的用户搜索行为全景图。这份数据不是终点,而是驱动所有数字营销决策的战略资产。将其从工具中导出,意味着我们可以进行更深度的挖掘、交叉分析与战略规划,这远比在工具界面内进行零散查看更具价值。
1. 构建内容护城河与捕捉长尾流量
海量的关键词库是构建系统性内容战略的基石。首先,它完整揭示了从核心头部词到海量长尾词的整个搜索生态。头部词决定了内容战略的核心方向,而数以万计的长尾词则精准地描绘了用户在特定场景下的具体需求与痛点。通过对这 50000 条关键词进行归类,我们可以系统地规划“主题集群”,以一个核心页面(Pillar Page)承载主要关键词,再通过一系列集群内容(Cluster Content)海量覆盖相关的长尾查询。这种结构不仅能极大地提升网站在搜索引擎眼中的权威性,还能构筑起竞争对手难以模仿的内容护城河,稳定捕获那些搜索意图明确、转化率极高的长尾流量。
2. 驱动精准广告投放与优化ROI
对于付费搜索(SEM)而言,一个庞大的关键词列表是提升广告效果和投资回报率(ROI)的生命线。导出的数据允许我们进行极致的精细化运营。我们可以根据关键词的意图、产品关联度等维度,将其划分成数千个高度相关的广告组,确保每一则广告文案都与用户的搜索词精准匹配,从而提升点击率。更重要的是,这是构建“否定关键词”列表的最有效途径。从 50000 条数据中筛选出与业务无关的搜索词,添加到否定列表中,能避免大量无效点击,直接节省广告预算。此外,结合搜索量、竞争度等数据,我们可以制定更具智慧的出价策略,将预算集中在那些最具商业价值的流量入口上。
3. 洞察市场趋势与发掘商业蓝海
关键词是市场需求最直接、最真实的晴雨表。一个包含 50000 条关键词的动态数据库,是持续进行市场洞察的强大工具。通过定期对比更新后的关键词列表,我们可以敏锐地捕捉到新兴的搜索趋势、消费者兴趣的转移以及季节性需求的变化。更深层次的价值在于,它能帮助我们发掘“商业蓝海”。当大量用户开始搜索某个问题的解决方案,而市场上尚未出现成熟的竞品或内容时,这就是一个明确的商业机会信号。无论是开发新产品线,还是提供新服务,这份关键词数据都提供了最直接的需求验证,帮助企业在竞争中抢占先机。
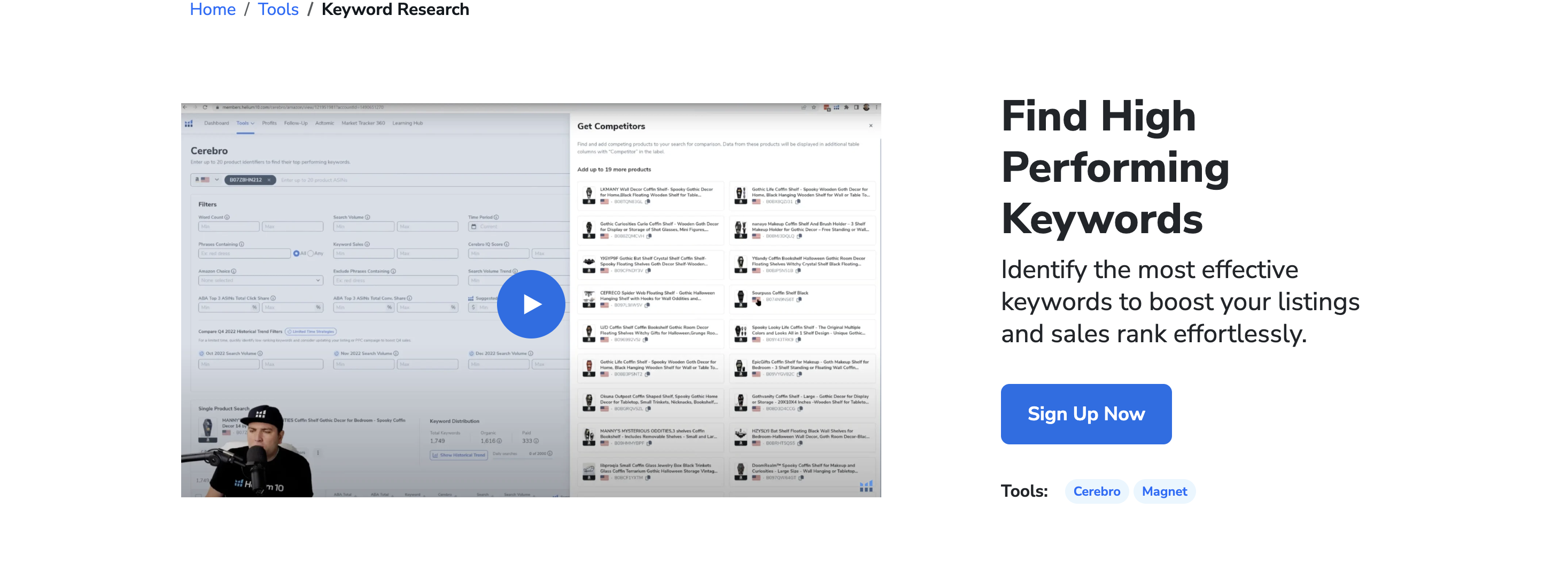
二、核心工具定位:Helium 10 Magnet 的深度应用
在亚马逊卖家的工具库中,Helium 10的Magnet远不止是一个简单的关键词挖掘工具,它是整个关键词策略体系的起点与引擎。其核心定位在于通过深度挖掘亚马逊搜索引擎自身的实时数据,为产品从诞生到成熟的全生命周期提供战略性数据支持。对Magnet的深度应用,直接决定了卖家能否在激烈的市场竞争中精准捕获流量,实现高效转化。
1. 从种子到长尾:构建全维度关键词词库
Magnet的基础应用是“拓词”,但深度应用在于“构建矩阵”。其价值并非简单地输入一个核心词,而是要求卖家以用户思维,系统性地构建关键词词库。
首先,运营者需围绕产品的“核心属性”、“功能”、“使用场景”、“目标人群”及“解决问题的痛点”等多个维度,设定不同的种子词。例如,对于一款“环保便携咖啡杯”,种子词不应只有“coffee cup”,还应包括“reusable mug”、“travel coffee cup”、“office coffee mug”、“eco-friendly gift”等。
其次,利用Magnet对这些不同维度的种子词进行深度挖掘。在获取的大量关键词结果中,需进行细致筛选与分类。这包括区分出高流量的大词、中等流量的核心词以及高转化的长尾词。长尾词尤其关键,如“12oz insulated coffee cup with lid”,它们虽然搜索量较低,但购买意图极强,是提升转化率的利器。最终,将这些词语整合成一个包含广泛、词组、精准三种匹配类型的全维度关键词矩阵,为Listing优化、PPC投放和站外营销提供全面的弹药支持,确保不遗漏任何一个潜在的客户搜索入口。
2. 精准狙击:赋能PPC广告活动的策略化部署
Magnet的数据是PPC广告活动的精准导航仪。深度应用Magnet,能将广告投放从“广撒网”升级为“精准狙击”。
在广告活动启动初期,可将Magnet筛选出的高相关性广泛词和核心词,用于喂养自动广告。此举的目的是让亚马逊的算法帮助我们发现那些我们自己未能想到的、但能带来转化的真实客户搜索词。
更重要的是在手动广告中的策略化部署。将Magnet词库进行拆分:对于竞争激烈、流量巨大的核心词,可建立专门的广告组,采用“词组匹配”进行测试,监控其ACoS(广告销售成本比),谨慎出价;而对于那些搜索量适中、且包含明确修饰词的长尾关键词,如“stainless steel coffee cup for car”,则应建立另一广告组,采用“精准匹配”模式。这类关键词竞争小,点击意图明确,往往能带来极低的ACoS和稳定的高转化率。此外,Magnet在拓词过程中产生的无关词汇(如配件、二手、维修等),应立即整理为“否定关键词列表”,从源头上杜绝无效点击,最大化广告预算的利用效率。
3. 洞察先机:挖掘细分市场与竞争蓝海
Magnet的最高阶应用,是将其作为市场洞察的雷达,发掘尚未饱和的蓝海市场。这需要卖家跳出既有产品的框架,从“需求”和“解决方案”出发进行探索。
例如,当你想进入宠物用品市场,但不确定具体方向时,可以从“pet anxiety solutions”或“dog grooming tools for shedding”这类问题导向的短语入手。Magnet的自动联想结果会揭示消费者的真实需求细节。如果在结果中发现“calming dog bed for anxiety”或“deshedding tool for short hair dogs”这类搜索量稳定但竞争分析(需配合Xray工具)显示头部卖家实力较弱的词,你就可能找到了一个潜力巨大的细分市场。
这种由需求反向推导产品机会的方式,能有效避开“宠物床”或“宠物梳”这类红海赛道的惨烈竞争。通过Magnet捕捉到的这些“蓝海词”,不仅为选品提供了数据依据,更意味着你可以提前布局关键词,抢占有利的搜索排名位置,在新品推广期就获得精准的自然流量与广告流量,从而建立早期的竞争优势。
三、第一步:精准的初始种子词设置
在任何以关键词为核心的策略布局中,初始种子词的设定是决定整个体系成败的基石。它并非简单的词语选择,而是对目标、领域与方向的第一次战略锚定。一个宽泛、模糊的种子词,如同在流沙上建造高塔,后续所有的扩展与优化都将事倍功半,甚至南辕北辙。因此,精准,是设置种子词的唯一要求。这种精准性体现在三个层面:对核心概念的聚焦、对语言结构的收敛,以及对潜在意图的预判。
1. 定义核心,而非描述现象
精准的第一步,是区分“核心概念”与“表面现象”。许多初学者易犯的错误是,将一个期望达成的结果或一个宏观的现象作为种子词。例如,“如何提升网站流量”便是一个典型的不良种子词。它描述的是一个现象或一个目标,过于宽泛,缺乏一个可供挖掘的实体核心。相反,我们应当深入思考,实现“提升流量”这一目标的“核心机制”是什么?可能是“SEO外链建设”,也可能是“社交媒体内容营销”。将“SEO外链建设”或“社交媒体内容营销”作为种子词,就完成了从现象到核心的聚焦。核心词具有内在的延展性和逻辑深度,它能自然地衍生出策略、工具、案例等一系列相关分支,而现象词只会引导出更多零散、不相关的问题。定义核心,就是为整个关键词体系找到一个强有力的“奇点”,确保后续所有能量都围绕其有序释放。
2. 使用“名词+限定词”公式进行收敛
在确定了核心概念后,下一步是使用语言工具对其进行精准收窄,避免歧义。最高效的方法是采用“核心名词 + 限定词”的组合公式。这个公式能强制性地将一个抽象概念具体化、场景化。核心词是基础,而限定词则是赋予其独特性的关键。限定词可以来源于多个维度:
- 行动/目标:例如,在“内容营销”这个核心词后,可以加上“转化率提升”,构成“内容营销转化率提升”。
- 场景/平台:例如,“小红书用户增长策略”,明确了操作的平台。
- 目标/对象:例如,“B2B企业获客”,精确了服务的客户类型。
- 属性/方法:例如,“低成本SEO”,限定了操作的预算和方法论。
通过这种公式化的组合,一个原本模糊的种子词被迅速打磨成一个棱角分明的“手术刀”,如“B2B企业低成本SEO策略”。它不仅清晰地定义了讨论的范围,也为后续的关键词扩展提供了明确的路径和框架,确保每一步扩展都在预设的轨道上进行。
3. 验证搜索意图与商业价值
一个看似完美的种子词,若不具备匹配的搜索意图或商业价值,仍是无效的。因此,设置的最后一道关卡是验证。首先,必须预判用户在搜索该词时的真实意图。是想获取知识(信息型)、比较产品(商业调查型),还是准备购买(交易型)?一个以品牌宣传为目的的种子词,与一个以直接销售为目的的种子词,其背后所匹配的意图截然不同。我们可以通过搜索引擎结果页面(SERP)的初步分析来验证:排名前列的是科普文章、产品评测页,还是在线购买页面?这些结果直接揭示了主流的搜索意图。其次,必须评估其商业价值。高搜索量但与自身业务无关的词是“虚荣指标”,低流量但高转化率的词才是“隐形金矿”。精准的种子词,必然是语言精确性、用户搜索意图与自身商业价值三者的高度统一。只有通过了这层验证,第一步的设置才算真正完成,为后续所有工作奠定了坚实且正确的起点。
四、第二步:解锁高级筛选与过滤器
当基础筛选的“仅包含”或“不包含”无法满足复杂数据分析需求时,高级筛选便成为我们精准洞察数据的关键武器。它不再是简单的“是/非”判断,而是允许我们构建逻辑、设定范围、应用公式,将数据检索从被动匹配升级为主动探索。掌握高级筛选,意味着你能够从海量数据中,以手术刀般的精确度,瞬间切分出目标信息集。
1. 构建复合条件:从单一筛选到逻辑组合
高级筛选的核心威力在于对逻辑条件“与(AND)”和“或(OR)”的灵活运用。单一条件的筛选,如只看“销售一部”的记录,只是起点。复合条件则能构建更精确的业务场景。例如,你需要找出“销售一部”中“业绩额大于10万元”的所有记录,这就是一个典型的“与”逻辑,要求所有条件必须同时满足。在筛选界面中,这通常表现为为同一列添加多个条件。而“或”逻辑则用于满足任一条件即可的情况,例如,筛选出“销售一部”或“产品类别为‘电子产品’”的所有记录,无论其所属部门或产品类别,只要满足其中之一,就会被纳入结果。理解并熟练运用这两种基本逻辑组合,是构建复杂筛选规则的基石,能够解决绝大部分多维度交叉查询的问题。
2. 精准定位数据:掌握数值、日期与文本的专项筛选
除了逻辑组合,针对不同数据类型的专项筛选功能,能让效率倍增。对于数值型数据,我们不再局限于手动输入阈值,而是可以直接应用“高于/低于平均值”、“前10项”(可自定义项数)、“介于……之间”等预设条件,快速定位异常值或关键绩效指标。日期筛选则更为智能,它提供了动态选项,如“今天”、“本季度”、“下月”等,这些筛选条件会随系统时间自动更新,无需手动调整,非常适合制作周期性报表。对于文本数据,通配符是不可或缺的工具。星号()代表任意多个字符,可用于模糊匹配,如输入“电脑”即可找到所有以“电脑”开头的记录。问号(?)代表单个任意字符,如“王?”可以精确匹配“王明”但不会匹配“王晓明”。通过这些专项工具,我们可以对数据进行更深层次、更具针对性的切片分析。
3. 超越界面:利用公式实现动态自定义筛选
当界面提供的所有预设条件都无法满足你的独特需求时,公式筛选便是终极解决方案。它允许你将任意Excel或Sheets函数作为筛选条件,实现完全自定义的动态逻辑。例如,你需要筛选出“单笔销售额高于该商品类别平均销售额”的记录。这个需求无法通过常规筛选完成,但通过公式则轻而易举。你可以创建一个辅助列,利用AVERAGEIF函数计算每行商品对应的类别平均销售额,然后在筛选器中设置条件,筛选出“实际销售额 > 类别平均销售额”的行。更高级的做法是直接在高级筛选的公式条件区域书写逻辑,如=C2>AVERAGEIF($B$2:$B$100, B2, $C$2:$C$100)(假设B列为商品类别,C列为销售额)。基于公式的筛选是动态的,当源数据更新时,筛选结果将自动重新计算和调整,赋予数据分析强大的生命力和响应速度。
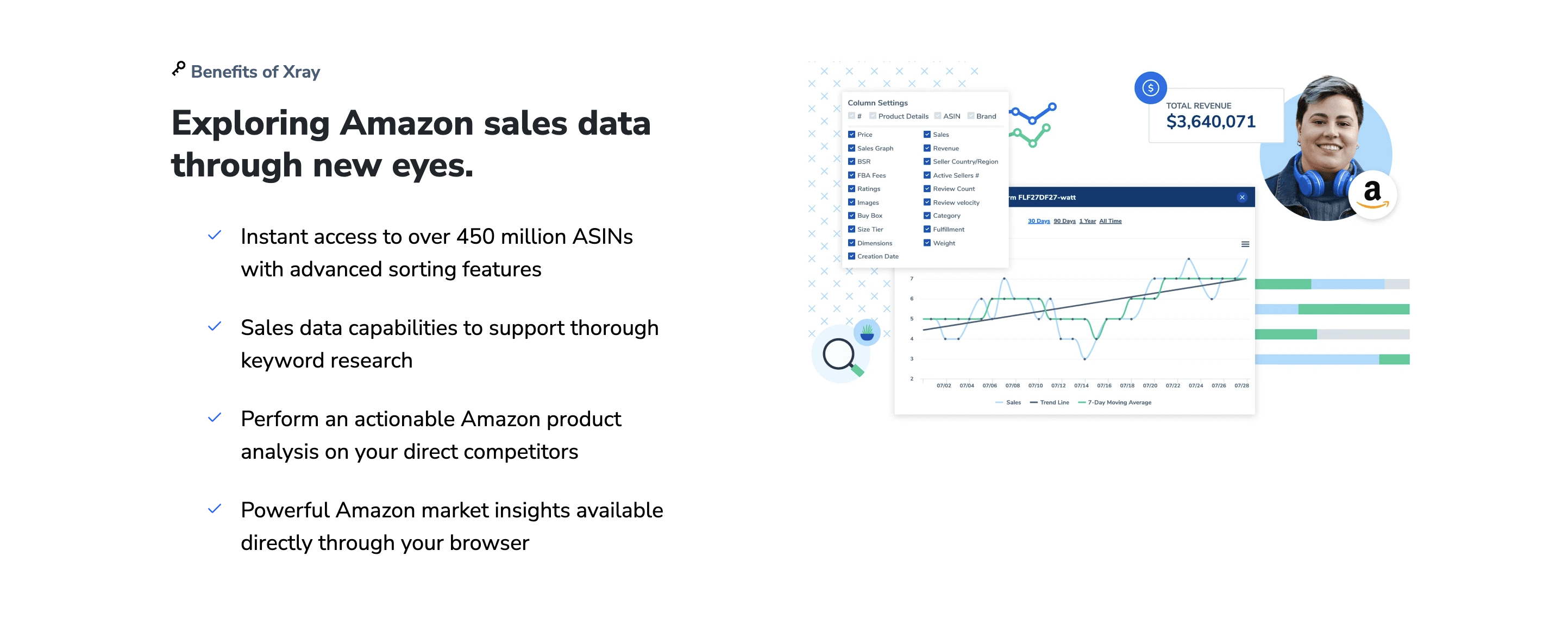
五、关键步骤:如何突破单次导出的数量限制
在数据处理与管理中,系统为保障性能与稳定性,通常会设置单次导出的数量上限,如一万条或五万条。当需要导出全量数据时,这一限制便成为瓶颈。突破此限制并非无解,关键在于采取正确的策略,将一次性大请求分解或绕过前端限制,实现数据的完整获取。
1. 分批次处理:化整为零的策略
这是最基础且普适性最强的解决方案。核心思想是将一次性的海量请求,拆解为多个小范围、可管理的批量任务,逐一执行后合并结果。具体操作方式灵活多样:
- 按时间维度切割: 如果数据带有时间戳(如订单创建时间、用户注册时间),可按月、周甚至日为单位,分批次导出不同时间段的数据。例如,先导出一月份的数据,再导出二月份,直至覆盖整个目标周期。
- 按ID范围切割: 利用数据库主键ID通常为自增数的特性,设置ID的起始和结束区间进行导出。例如,先导出ID从1到10000的数据,再导出10001到20000,循环往复。此方法效率高,且不易造成数据遗漏。
- 利用系统分页参数: 如果系统支持分页查询(如URL中包含
page和pageSize参数),可以编写简单的脚本,循环修改页码参数,逐页抓取数据并存储。此方法无需后端配合,是前端或测试人员快速验证的常用手段。
分批次处理的优势在于无需改动系统代码,适用于任何具备筛选或分页功能的界面,是应对紧急导出需求的“曲线救国”良策。
2. 后端脚本与异步任务:彻底解放前端
当数据量达到百万甚至千万级别时,分批次处理不仅效率低下,长时间占用浏览器资源也可能导致页面崩溃。此时,最佳实践是构建后端的异步导出任务。
用户在前端点击“导出全量数据”按钮后,请求发送至服务器。服务器立即响应并创建一个后台任务,将此任务加入消息队列(如RabbitMQ, Kafka),然后立刻向前端返回“导出任务已创建,处理完成后将邮件通知您”的提示。后台的工作进程(如Python的Celery、Java的 ScheduledExecutorService)会从队列中取出任务,在服务器端执行高耗时的数据查询、文件生成(如Excel或CSV)操作。任务完成后,系统将生成的文件存储至临时地址,并通过邮件或站内信将下载链接发送给用户。
此方案将高负载的导出操作与用户请求彻底解耦,保证了前端的即时响应和整个系统的稳定性,是处理大规模数据导出的工业级标准做法。
3. 直连数据库与API调用:终极技术方案
对于拥有系统更高权限的技术人员,还有更直接的路径可以绕过应用层所有限制。
- 直连数据库导出: 如果具备数据库访问权限,可以直接使用数据库客户端工具或命令行工具。例如,使用MySQL的
mysqldump命令导出特定表,或在数据库中执行SELECT ... INTO OUTFILE语句,将查询结果直接写入服务器文件。这是速度最快、资源占用最可控的方式,但操作者必须对数据库结构有清晰了解。 - 调用开放API: 如果系统提供了数据查询的API接口,且该接口支持分页,那么最佳方式是编写一个自动化脚本(如Python或Node.js脚本)。脚本通过循环调用API,自动处理分页逻辑和异常重试,将所有数据拉取并整合到本地文件。相比于模拟浏览器操作,API调用更稳定、高效,是数据集成与自动化分析的首选。
这两种方法技术门槛较高,需要相应的权限和开发能力,但它们提供了无与伦比的效率和灵活性,是突破一切导出限制的终极武器。

六、一键导出实战:从搜索到 CSV 文件
将海量线上数据转化为可供分析的本地文件,是现代业务决策的关键一步。本章将深入剖析“一键导出”功能的完整实现流程,从精准的数据检索到最终的CSV文件生成,提供一个清晰、无冗余的实战指南,帮助用户高效地将屏幕信息转化为结构化资产。
1. 精准定位:构建高效搜索策略
导出的价值始于高质量的搜索结果。在点击“导出”之前,必须确保当前视图中的数据正是你所需要的。这要求我们掌握高效的搜索与筛选技巧。首先,利用核心关键词进行初步匹配,快速缩小数据范围。其次,结合多维度筛选器,如日期范围、产品类别、用户状态或地理区域,进行精细化过滤。例如,若需导出上一季度华东地区的流失用户列表,就必须同时设定时间、地域和用户状态三个筛选条件。对于复杂需求,部分高级系统还支持使用特定的搜索语法(如布尔运算符、通配符),实现更精准的查询。记住,一个精准的搜索策略能从源头上杜绝数据冗余,确保最终导出的数据集纯粹、准确,为后续分析奠定坚实基础。
2. 键触发:无缝导出的核心逻辑
当搜索结果以列表形式清晰呈现后,界面上的“导出为CSV”按钮便是整个流程的触发器。其背后是一套严谨的后端处理逻辑。点击按钮后,前端会将当前的搜索条件(关键词、筛选器参数、分页信息等)打包成一个请求发送至服务器。后端服务接收到请求,并不会简单抓取当前页面的可见数据,而是复用完全相同的查询逻辑,直接对接数据库,完整、无遗漏地检索出所有符合条件的数据集,有效规避了因分页导致的数据缺失。随后,系统将这些数据动态生成符合CSV标准(逗号分隔值)的文本流,并设置正确的HTTP响应头(如Content-Disposition: attachment),从而引导浏览器触发下载行为,而非在页面上直接显示文本内容。整个过程对用户而言是“一键”的,但系统已在后台完成了数据聚合、格式化和响应引导的全部工作。
3. 数据到手:验证与后续应用
文件下载完成后,工作并未结束。首要任务是进行数据验证。使用Excel、Google Sheets或任何文本编辑器打开CSV文件,核对以下几点:列头(字段名)是否与预期一致?数据总行数是否与系统显示的总量相符?是否存在乱码或特殊字符导致的格式错乱(这通常与文件编码有关,推荐使用UTF-8编码以确保兼容性)?验证无误后,这份CSV文件便成为了一个强大的数据载体。它可以直接用于制作数据透视表、绘制业务图表,进行快速的可视化分析;也可以作为数据源,无缝导入到BI工具、数据库或数据分析平台中,进行更深层次的挖掘、建模与长期归档,真正实现从原始数据到业务洞察的转化。
七、数据清洗:如何快速筛选与去重
数据清洗是数据分析的基石,而筛选与去重则是其中最核心、最高频的操作。高效地完成这两项任务,能从源头上保证数据质量,为后续的分析与建模打下坚实基础。掌握正确的工具与方法,可以将数小时的手工操作压缩至几分钟。
1. 高效筛选:精准定位目标数据
筛选的目的在于从海量数据中,根据特定条件快速提取出我们关心的子集。不同的工具提供了不同的实现路径,但其核心逻辑一致。
在Excel中,最常用的是“自动筛选”功能。通过列标题的下拉菜单,可以轻松进行文本、数字、日期的模糊或精确筛选。对于多条件组合的复杂筛选,如“销售额大于10000且区域为‘华北’”,则需使用“高级筛选”。它允许用户在单独的区域设置 criteria 范围,实现“与(AND)”和“或(OR)”的复杂逻辑组合,一键得到精确结果。
对于Python用户,Pandas库的布尔索引是功能最为强大的筛选工具。其语法简洁直观,例如,df[(df['sales'] > 10000) & (df['region'] == '华北')] 即可完成上述复杂筛选。&、|、~ 分别代表逻辑与、或、非,括号的使用能有效区分运算优先级。此外,.isin() 方法可用于多值匹配,.str.contains() 结合正则表达式则能处理更为复杂的文本匹配需求,实现超高自由度的筛选。
在SQL数据库中,筛选的核心是WHERE子句。一条简单的 SELECT * FROM sales_table WHERE sales > 10000 AND region = '华北'; 即可完成任务。SQL的优势在于其处理大数据集时的性能,以及LIKE、IN、BETWEEN等丰富的操作符,使得查询逻辑清晰且高效。
2. 极速去重:保证数据唯一性
重复数据是污染数据集的常见“元凶”,它会扭曲统计结果,占用不必要的存储空间。去重操作旨在根据一个或多个关键字段,保留唯一的数据记录。
Excel提供了图形化的去重方案。在“数据”选项卡下选择“删除重复项”,勾选作为唯一标识的列(如“订单ID”或“用户ID”),Excel会自动删除后续重复的记录,仅保留第一条。此方法操作简单,非常适合处理中小型数据表的快速去重。
Python Pandas的 drop_duplicates() 方法则更为灵活。缺省情况下,它会基于所有列进行全匹配去重。其强大之处在于参数控制:通过 subset=['订单ID'] 可指定基于特定列去重;通过 keep='first' 或 keep='last' 可明确保留第一条还是最后一条记录;设置 keep=False 则会删除所有出现过的重复项。例如,df.drop_duplicates(subset=['用户ID', '日期'], keep='last') 可以精准地保留每个用户每天的最后一次操作记录。
在SQL中,SELECT DISTINCT 用于返回唯一不同的值,但它会基于所有选定列进行去重,灵活性有限。更专业的去重方法是使用窗口函数 ROW_NUMBER()。例如,要对orders表按user_id分组并保留最新的订单,可以编写:WITH RankedOrders AS (SELECT *, ROW_NUMBER() OVER(PARTITION BY user_id ORDER BY order_date DESC) as rn FROM orders) DELETE FROM RankedOrders WHERE rn > 1;。这种方式能在数据库层面高效完成复杂条件下的去重,是数据仓库ETL流程中的标准操作。
掌握上述针对不同场景的筛选与去重技巧,是每一位数据处理人员的必备技能,它直接决定了数据准备的效率与最终分析的可靠性。
八、战略应用一:构建强大的 PPC 关键词库
在付费点击(PPC)广告的世界里,关键词是连接用户意图与商业 offer 的核心桥梁。一个强大的关键词库并非简单的词语堆砌,而是一个经过深思熟虑、结构化且持续演进的战略资产。它是实现精准触达、控制预算成本、提升广告质量得分并最终驱动高投资回报率(ROI)的基石。构建这样一个关键词库,需要系统性的方法,从深度挖掘到战略组织,再到生命周期管理。
1. 核心原则:从广度到深度的关键词挖掘
构建关键词库的第一步是全面而深入的挖掘,确保覆盖所有潜在的客户触点。这个过程应遵循“从广度到深度”的原则。
首先,确定核心关键词。这些是与你的业务、产品或服务直接相关、搜索量较高的词语,构成了关键词库的根基。例如,一家在线教育公司,其核心关键词可能是“在线课程”、“职业技能培训”。以核心关键词为圆心,向外扩展至长尾关键词。长尾关键词通常由3个以上词语组成,搜索量较低,但用户意图更明确,转化率往往更高。例如,“Python编程入门在线课程”、“零基础学习数据分析哪家好”。
更重要的是,必须基于用户搜索意图进行分类。这能让你在不同的客户决策阶段施加影响:
1. 信息型意图:用户在寻找信息、解决方案,常用“如何”、“什么是”、“指南”等。例如,“如何选择编程语言”。这类词适合通过提供有价值的内容来建立品牌信任。
2. 导航型意图:用户已明确目标品牌或产品。例如,“Coursera 在线课程”。优化此类词能抢占品牌流量或进行精准的竞品拦截。
3. 交易型意图:用户购买意愿最强,常伴随“购买”、“价格”、“折扣”、“优惠”等词。例如,“购买数据分析课程”、“UI设计培训优惠”。这是转化效果最直接的关键词,应作为预算分配的重点。利用Google关键词规划师、Ahrefs、SEMrush等工具,可以高效地完成这一阶段的挖掘与意图分析工作。
2. 结构化组织:从列表到战略矩阵
一个未经组织的关键词列表是无力的,甚至会导致预算浪费。真正的力量来自于结构化的组织,将其转化为一个可执行的战略矩阵。
第一步是进行关键词分组。将语义、意图和主题高度相关的关键词划分到同一个广告组中。例如,“Python入门课”和“Python基础班”应放在一个广告组,而“数据分析进阶”则应另立新组。这能确保广告文案与关键词高度相关,从而提升质量得分。
更进一步,我们应构建一个关键词矩阵。这个矩阵以产品/服务类别为一个维度,以用户意图(或用户旅程阶段)为另一个维度。例如:
| | 信息型(研究) | 交易型(购买) |
|---|---|---|
| 编程课程 | “编程入门指南” | “Python在线课程购买” |
| 设计课程 | “UI/UX设计趋势” | “Figma培训班价格” |
这种矩阵化的组织方式,使得我们可以为矩阵中的每一个单元格(如“编程课程-信息型”)撰写极具针对性的广告文案,并引导至最匹配的着陆页。它将关键词管理从混乱的列表提升为清晰的作战地图,让预算分配、效果归因和策略优化都变得有据可依。
3. 持续优化:关键词库的生命周期管理
关键词库并非一成不变,它是一个需要持续维护和优化的生命体。忽视这一点,再强大的初始库也会逐渐失效。
核心工具是搜索词报告。定期分析这份报告,可以洞察用户真实使用的搜索词。对于那些能带来转化但尚未添加为关键词的搜索词,应立即以“精准匹配”模式添加到相应广告组中,以捕获更多高质量流量。同时,对于大量无关或低效的搜索词,必须果断地将其添加为否定关键词,这是防止预算流失、提升广告效率最直接的手段。
此外,要定期对关键词库进行效果复盘。根据点击率(CTR)、转化率(CVR)和单次获客成本(CPA)等指标,识别并暂停表现持续低迷的关键词,将预算倾斜给高绩效的关键词。同时,关注市场趋势、季节性变化和新兴热点,主动挖掘和测试新的关键词机会,确保关键词库始终与市场保持同步,持续为业务增长提供动力。
九、战略应用二:优化 Listing 标题与五点描述
Listing是产品与消费者的第一次线上“对话”,其质量直接决定了流量的获取与转化效率。标题是吸引点击的“黄金广告位”,五点描述则是促成下单的“核心推销员”。二者的优化,必须精准且协同,方能最大化Listing价值。
1. 标题:流量入口的黄金公式
标题是搜索算法抓取与用户第一印象的核心,其优化需兼顾算法逻辑与人类阅读习惯。一个高转化标题的黄金公式为:核心关键词 + 品牌/型号 + 关键属性/卖点 + 适用场景/人群。
首先,将最核心、流量最高的关键词置于标题最前端,这是抢占搜索结果的黄金位置。例如,销售“便携式咖啡机”,“便携式咖啡机”必须紧随品牌名出现。其次,在标题中自然融入高价值属性词,如“大容量”、“全自动”、“防水材质”等,这些是用户筛选决策的关键依据。务必杜绝无关关键词的堆砌,这不仅会降低可读性,还可能被平台算法判定为作弊,反而影响排名。最后,考虑移动端显示限制,确保前60个字符已完整展示核心卖点,因为这是用户无需点击即可看到的最关键信息。一个优秀的标题,既是对搜索流量的精准拦截,也是对产品价值的高度浓缩。
2. 点描述:从兴趣到决策的加速器
如果说标题解决了“被看到”的问题,五点描述则要解决“被选择”的问题。它的核心任务不是罗列功能,而是将功能转化为用户可感知的利益,直击痛点,构建信任。
每一条五点描述都应遵循“痛点/利益点 + 属性/功能支撑 + 价值升华”的结构。开头用简洁有力的短语或符号,如“【持久续航】”或“【一分钟快装】”,迅速抓住对应需求用户的注意力。接着,用一句话解释支撑该利益点的产品特性,如“内置5000毫安时锂电池”。最终,将这一特性与用户生活场景关联,描绘使用后的美好体验,如“告别电量焦虑,满足一整天户外作业需求”,完成从物理属性到情感价值的跨越。此外,五点描述的排序应有逻辑。通常第一点展示最核心的差异化优势,中间两点支撑次要卖点,第四点可涵盖材质、尺寸等细节,最后一点则可用于售后服务承诺,彻底打消购买疑虑。通过这种结构化、场景化的阐述,五点描述将成为说服消费者下单的最强助推力。
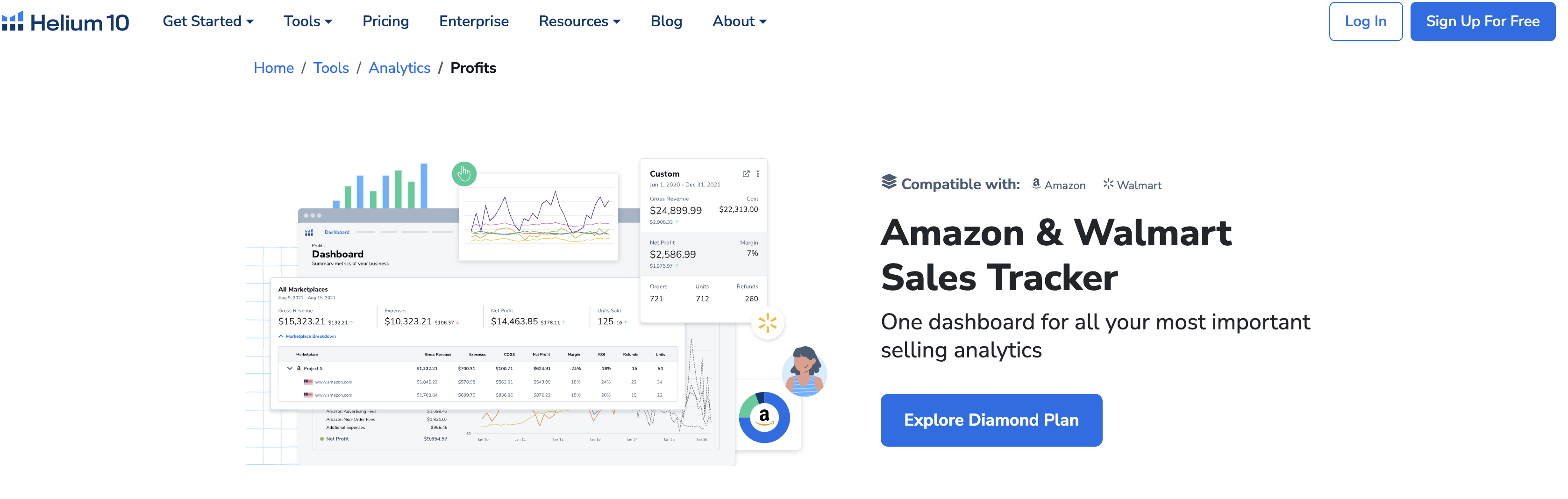
十、进阶技巧:结合 Cerebro 挖掘竞品流量词
Cerebro 不仅是关键词查询工具,更是亚马逊卖家的战略雷达。其核心价值在于通过反向ASIN查询,精准解构竞品的流量来源,将对手的成功经验转化为你自己的增长动力。要实现从“会用”到“精通”的跨越,必须掌握系统化的挖掘与分析方法。
1. 精准锁定核心竞品,构建分析基准
无效的输入必然导致无效的输出。启动Cerebro的第一步,是建立一个具有代表性和参照价值的竞品矩阵。切忌只分析一个“假想敌”。正确的做法是:选取3-5个不同维度的核心竞品。首先,纳入1-2个品类巨头,它们占据着最核心的流量词,代表了市场的天花板。其次,选择2-3个与你体量、价格、Review数量相近的直接竞争者,他们的关键词策略更具现实参考意义。
将这些ASIN批量导入Cerebro后,首要关注的是“共享关键词”数据。这些是多个头部竞品都在争夺的流量高地,是你必须站稳脚跟的战场。通过这个共享词库,你可以快速勾勒出整个品类的流量版图和用户心智模型,为后续的词库扩张和定位筛选出坚实的基准。例如,若发现所有竞品都在争夺一个你未曾使用的宽泛词,这便是一个强烈的优化信号。
2. 运用高级筛选,高效识别高价值流量词
面对Cerebro生成的数千个关键词,数据筛选能力是区分新手与高手的关键。目标是快速定位那些“高搜索量、低竞争度、高转化潜力”的黄金机会词。首先,设置基础的“搜索量”过滤器,剔除月搜索量低于500(具体数值根据品类调整)的低效长尾词,集中精力在能带来可观流量的词汇上。接着,引入“竞争程度”指标,筛选出竞争度低于0.7的词汇,避开与巨头在红海词汇上的直接硬碰硬。
最核心的技巧在于利用“Cerebro IQ得分”或“机会得分”进行降序排列。这个综合指标已经为你权衡了搜索量、竞争度和匹配度等多重因素,得分最高的词汇往往就是唾手可得的果实。此外,重点审查“竞品排名”列:找出那些竞品排名在前十,而你自身毫无排名或排名极低的关键词。这些是你的“短板词”,也是最快见效的增量切入点。将这部分词整理出来,意味着你找到了可以直接从对手手中抢夺流量的精确弹药。
3. 构建词库矩阵,赋能Listing与PPC
挖掘出的关键词绝不能简单地堆砌。必须建立一个动态的词库矩阵,将数据洞察转化为可执行的优化策略。将筛选后的关键词分为三类:核心流量词、精准转化词和机会拓词。
核心流量词(高搜索量、高竞争)应优先布局在Listing的标题、五点描述的靠前位置,并作为PPC自动广告和广泛/词组匹配广告的核心,用于抢占曝光。精准转化词(通常包含产品属性、功能、使用场景等)则应深度融入五点描述、A+页面和产品描述中,同时开启PPC精准匹配广告,以最大化转化率。最后,机会拓词(新发现的、相关性强的词汇)可作为Listing后端搜索词的补充,并为测试新的PPC广告活动提供素材,持续探索新的流量蓝海。通过这种结构化的词库管理,你的每一个优化动作都将基于精准的数据情报,实现流量与销量的双重突破。
- 我的微信
- 这是我的微信扫一扫
-

- 我的微信公众号
- 我的微信公众号扫一扫
-