
- A+
一、什么是关键词索引以及为什么它至关重要
关键词索引,本质上是为数字内容创建的一本超级目录。它如同书籍末尾的索引页,但其规模、速度和复杂性远超传统索引。它不是简单罗列词汇,而是通过技术手段,将海量非结构化的文本内容,转化为一个可以被快速查询和匹配的结构化数据库。这个看似后台的技术过程,却是整个信息检索世界得以运转的基石,其重要性体现在每一个搜索请求的背后。
1. 关键词索引的核心机制:从混乱到有序
关键词索引的构建过程,是一个将无序信息结构化的精密工程。首先,搜索引擎的爬虫会抓取网页、文档等各种内容。接着,系统会解析这些内容,提取出核心词汇(即关键词),并忽略“的”、“是”等无意义的停用词。最关键的一步在于创建“倒排索引”。传统的索引是“文档 -> 包含的词”,而倒排索引则完全相反,它记录的是“关键词 -> 出现该关键词的文档列表”。例如,系统不再记录“A文章讲了索引和排名”,而是记录两条独立索引:“索引” -> [A文章, B文章],“排名” -> [A文章, C文章]。这种结构使得搜索引擎在接到用户搜索“索引”的指令时,无需遍历所有文章,只需直接查询“索引”这个词对应的文档列表即可,从而实现毫秒级的响应速度。

2. 为何关键词索引至关重要:连接用户与内容的桥梁
关键词索引的价值,体现在它对用户、内容创作者和平台三方构成的巨大影响上。
对于用户而言,索引是高效信息获取的保障。在没有索引的互联网海洋中搜索,无异于大海捞针。索引机制将检索时间从天级别压缩至秒级,极大地提升了用户体验,让海量信息变得真正可用。
对于内容创作者和企业而言,索引是内容被发现的唯一途径。无论内容多么优质,如果没有被搜索引擎的关键词索引系统收录,它就如同信息孤岛,无法触达潜在用户。因此,理解索引原理,进行合理的SEO(搜索引擎优化),确保内容能被正确、高效地索引,直接关系到网站的流量、品牌曝光乃至商业转化。
对于搜索引擎或内容平台本身,索引是其能够高效管理和索引海量、不断增长的信息的技术前提。没有强大的索引系统,平台的扩展性和稳定性将无从谈起。
综上所述,关键词索引并非一个可有可无的技术选项,而是整个信息检索大厦的基石。它默默无闻地工作,却将人类从信息过载的混乱中解放出来,构建了一个有序、高效、可访问的数字世界。

二、H10 Index Checker 简介:你的关键词诊断利器
在亚马逊这片竞争激烈的海洋中,产品的可见性直接决定了其生死。而“索引”便是获得可见性的第一步,是连接产品与潜在买家的第一座桥梁。无论你的Listing优化得多么完美,若一个关键词未被亚马逊A9算法索引,那么对于搜索该词的买家而言,你的产品就如同不存在。H10 Index Checker正是为此而生的精密诊断工具,它能快速、准确地告诉你,你的ASIN是否被特定关键词“收录”,从而为你的流量战略提供最根本的数据支持。
1. 为何索引是流量的命脉?
索引与排名是两个不同但紧密关联的概念。排名指的是产品在搜索结果中的位置,而索引则是产品有资格参与排名的“入场券”。一个关键词未被索引,意味着你的产品完全不在该词的搜索结果池里,自然也就无从谈及点击和转化。这会导致两个严重后果:首先,你将彻底失去该关键词带来的所有自然流量,这是成本最低、转化意愿最强的流量来源。其次,即使你投放PPC广告,一个未被索引的关键词也可能导致广告质量得分低下,推高单次点击成本,甚至使广告难以获得展示。因此,确保核心关键词被有效索引,是所有流量策略的基石。
H10 Index Checker的价值在于其极致的效率和准确性,它将繁琐的人工排查过程简化为一次点击。其核心功能体现在以下几点:第一,快速验证。用户只需输入ASIN和目标关键词,系统便会在数秒内返回明确的“已索引”或“未索引”结果,无需再手动翻阅数百页搜索结果。第二,深度搜索。不同于简单的表面检查,该工具模拟真实用户搜索,深入挖掘搜索结果的后端,确保诊断结果的可靠性。第三,批量操作。对于需要同时监控多个关键词或多个ASIN的专业卖家而言,其批量检查功能极大地提升了工作效率,使得大规模的Listing健康度审查和竞品索引分析成为可能。

2. 从诊断到行动:优化策略的起点
获得“未索引”的诊断结果并非终点,而是优化行动的明确起点。在新品上架初期,你可以用它来追踪核心关键词的索引进度,确保产品尽快获得曝光。在完成Listing优化(如修改标题或五点描述)后,它可以立即验证修改是否成功触发了算法的重新索引,让优化效果立竿见影。当某个关键词的自然排名突然消失时,第一步就应使用该工具检查索引状态。如果结果显示“未索引”,便直接指向了可能是算法惩罚或Listing内容违规等深层问题,帮助你迅速定位故障源头,而不是在无效的广告投放上继续浪费金钱。H10 Index Checker不仅是一个检查工具,更是你制定和调整SEO与广告策略的战略罗盘。
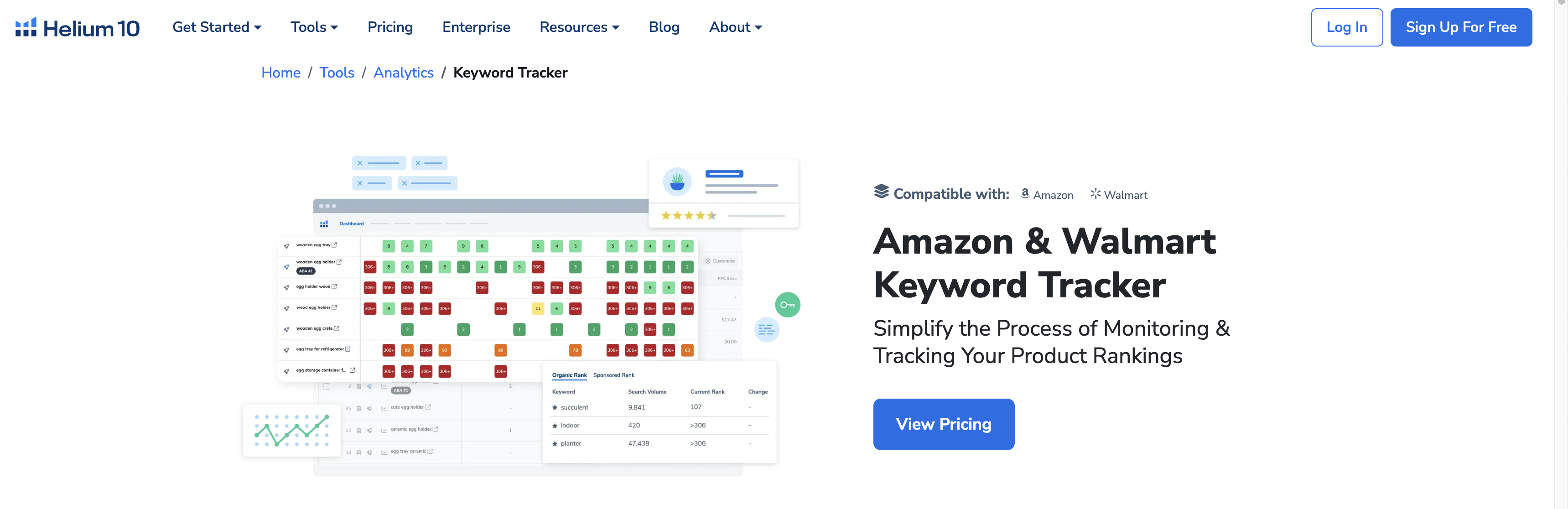
三、分步指南:如何使用 H10 IndexChecker 检查索引状态
Helium 10 的 IndexChecker 是亚马逊卖家精准监控产品搜索可见性的核心工具。它通过查询特定ASIN是否被目标关键词索引,帮助卖家诊断Listing的健康状况、验证优化效果及排查流量问题。本指南将为您提供清晰、无废话的操作步骤与结果解读。
1. 核心操作流程:输入与查询
IndexChecker 的使用界面直观,但正确的输入是获得准确结果的前提。
-
访问工具:登录 Helium 10 账户,在工具库中找到并点击 IndexChecker。该工具通常被归类在“研究”或“运营”工具组下。
-
输入ASIN:在顶部的输入框中,粘贴您想要检查的产品ASIN。IndexChecker 支持单个查询,也支持通过上传CSV文件进行批量检查,这对于拥有大量ASIN的卖家而言,能极大地提升效率。
-
输入关键词:在下方的关键词输入框中,逐行填入您希望检查的关键词。这些关键词应是您期望产品能被搜索到的核心词、长尾词或属性词。建议将最重要的关键词放在前列,以便快速评估。
-
执行查询:完成输入后,点击“检查索引状态”按钮。系统将开始模拟亚马逊的搜索过程,逐一验证您的ASIN是否与每个关键词相关联。查询速度取决于关键词数量,通常在几秒到一分钟内完成。
-
获取结果:查询结束后,页面会生成一个清晰的表格,列出您输入的每一个关键词及其对应的索引状态。

2. 解读查询结果:状态分析与应对策略
得到结果只是第一步,理解其背后的商业意义并采取行动才是关键。IndexChecker 的结果主要分为两种状态:
-
已索引:此状态为理想结果,表示亚马逊的搜索引擎已认定您的ASIN与该关键词高度相关。当顾客搜索该词时,您的产品具备了出现在搜索结果中的资格。请注意,“已索引”不等于“有排名”,它只是入场券。如果产品已索引但排名很低,您需要关注 Listing 的优化质量、销量、转化率及广告投入等因素以提升排名。
-
未索引:这是一个警示信号。它意味着亚马逊没有将您的产品与该关键词关联起来,搜索该词绝对找不到您的产品。原因通常有三种:一是新品上架不久,亚马逊仍在处理和索引中,通常需要24-72小时;二是关键词并未出现在标题、五点描述或后台搜索词中,系统无法识别其相关性;三是Listing存在隐性或显性的违规,如被抑制,导致部分或全部关键词失效。
- 应对策略:首先,立即核对Listing文案,确保目标关键词已自然植入。其次,若确定关键词已植入但仍“未索引”,请耐心等待24小时后再次查询。若持续“未索引”,需检查卖家中心的“管理库存”页面,查看是否有Listing被抑制的警告,并根据提示进行修复。
3. 高级应用场景与最佳实践
将 IndexChecker 融入日常工作流程,能最大化其价值。
-
新品发布追踪:新品上线后,每日使用 IndexChecker 检查核心关键词库,可以直观地追踪亚马逊索引您的Listing的速度和广度,帮助您判断新品是否顺利进入搜索引擎的“视野”。
-
优化效果验证:当您对Listing的标题或五点描述进行重大修改后,可在24-48小时后使用此工具,验证新增或修改的关键词是否成功被索引。这避免了盲目猜测,让优化工作有据可依。
-
流量下滑诊断:当您的自然订单骤减时,IndexChecker 是最快的排查工具之一。用它检查主要引流词的索引状态,可以快速判断是否因失去关键索引而导致流量入口关闭。
通过以上步骤,您可以系统性地利用 IndexChecker 精准掌控产品在亚马逊搜索生态中的可见性,为精细化运营提供坚实的数据支持。
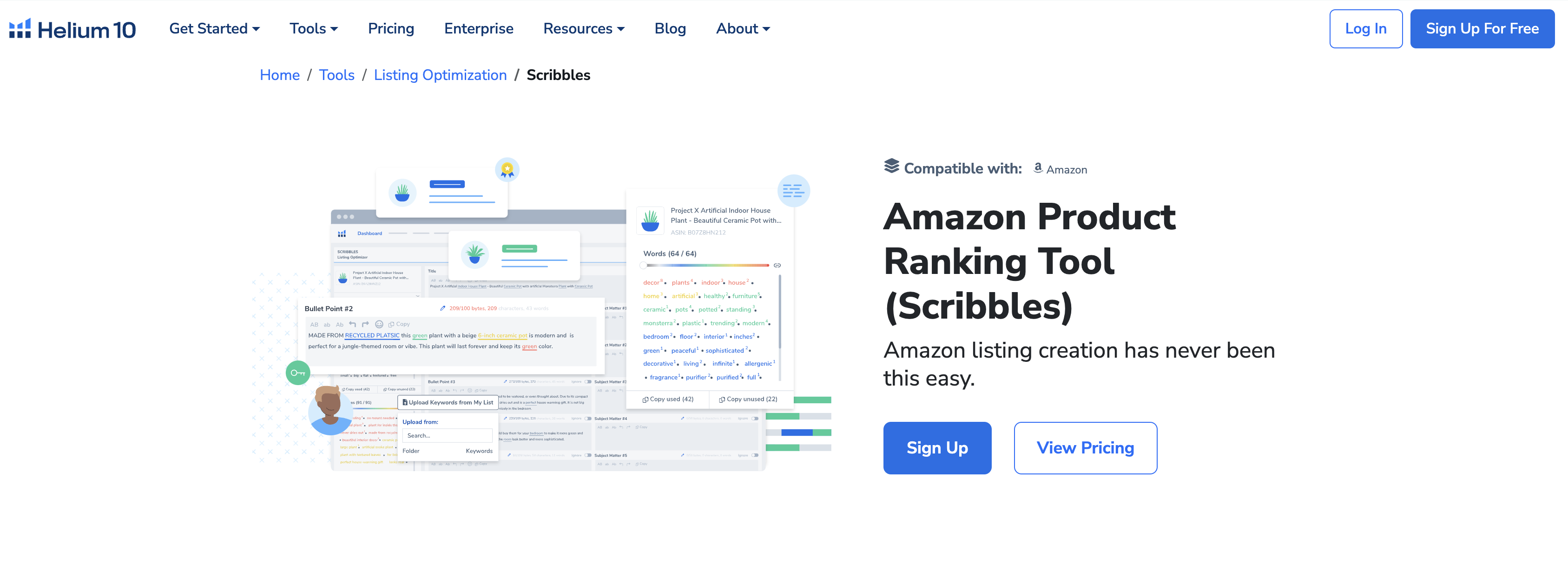
四、解读检查结果:“已索引”与“未索引”的含义

1. “已索引”:搜索引擎的“已收录”认可
“已索引”意味着搜索引擎(如谷歌、百度)的爬虫已经成功发现、抓取并分析了你的页面内容,并将其数据存入了庞大的搜索引擎数据库中。这相当于你的页面获得了在搜索结果中展示的“入场券”。只有被索引的页面,才有可能在用户搜索相关关键词时出现在搜索结果页(SERP)中。需要明确的是,“已索引”不等于高排名,它仅仅是参与排名的前提。一个页面被索引,表明它在技术层面和内容基础层面通过了搜索引擎的初步审核,被认为是值得收录的、有价值的(或至少是合规的)内容。检查页面是否被索引,最直接的方法是使用搜索引擎的site:语法操作符,例如在谷歌搜索site:yourdomain.com/specific-page,如果返回了对应的结果,则证明该页面已成功索引。
2. “未索引”:页面隐形的警示信号
“未索引”则代表你的页面对于搜索引擎来说是“隐形”的。无论内容多么优质,设计多么精美,只要处于未索引状态,它就无法通过任何自然搜索查询被用户发现,这也就切断了该页面获取搜索引擎流量的所有可能性。“未索引”通常分为两种情况:一是搜索引擎尚不知道该URL的存在,可能是由于缺乏内外链接指向,导致爬虫无法发现;二是搜索引擎已经发现或访问过该URL,但因特定原因选择不将其收录。后者往往是更常见且需要优先解决的问题。使用site:语法搜索页面URL,若无任何结果,或在Google Search Console的“索引”报告中看到“未收录”的提示,都表明页面处于“未索引”状态。

3. 核心归因:为何页面会“未索引”?
导致页面“未索引”的原因多样,必须逐一排查才能对症下药。常见原因包括:
-
noindex指令:页面HTML代码中包含<meta name="robots" content="noindex">标签,这是最直接的原因。该标签明确告知搜索引擎请勿将此页面收录进索引库,通常用于感谢页、内部搜索结果页等不希望公开访问的页面。 -
Robots.txt文件屏蔽:网站的robots.txt文件通过
Disallow指令禁止了搜索引擎爬虫对该页面或所在目录的访问。如果爬虫无法访问,自然也就无法完成索引。这是一种比较“粗暴”的屏蔽方式。 -
内容质量问题:搜索引擎判定页面内容为低质量、重复或稀薄内容。例如,大量复制粘贴的内容、字数过少的页面,或与网站主题无关的内容,都可能被搜索引擎主动拒绝索引。
-
抓取错误:页面在抓取时返回服务器错误(如5xx错误)、长时间加载或存在复杂的重定向链,这些技术问题会导致爬虫无法有效获取页面内容,从而放弃索引。
-
孤立页面:页面没有任何来自站内或站外的有效链接,形成了“信息孤岛”。搜索引擎爬虫依赖于链接来发现新页面,一个完全孤立的页面很难被发现。
五、关键词未被索引?常见原因与排查步骤
当您精心优化的页面及目标关键词未被搜索引擎索引时,意味着它将无法出现在任何自然搜索结果中,所有SEO努力都将付诸东流。索引是排名的前提,解决索引问题刻不容缓。以下是一套系统化的排查思路,旨在快速定位并解决问题。核心工具推荐使用 Google Search Console (GSC),它能提供最直接的诊断信息。
1. 技术性障碍:排查访问权限问题
这是最常见且最容易排查的一类原因,核心在于确认搜索引擎爬虫是否被允许访问并索引您的页面。
首先,检查 Robots.txt 文件。该文件是网站根目录下的一个指令文件,用于告知爬虫哪些路径可以抓取,哪些禁止。误用 Disallow: / 指令会封锁整个网站,而 Disallow: /specific-page/ 则会阻止特定页面。使用GSC的“Robots.txt 测试工具”可以验证目标URL是否被意外屏蔽。
其次,审查页面的 Meta Noindex 标签。在HTML代码的 <head> 部分,如果存在 <meta name="robots" content="noindex">,就等于明确告诉搜索引擎“不要索引此页面”。这通常由CMS插件、主题设置或代码修改错误导致。即使Robots.txt允许抓取,Noindex标签也有最高优先级。
最后,检查 Canonical 标签设置。Canonical(rel="canonical")标签用于指定页面的“主版本”,以解决重复内容问题。如果页面A的Canonical指向了页面B,搜索引擎会认为页面B才是需要索引的权威版本,从而忽略页面A。确保页面的Canonical URL正确指向其自身,或者指向您希望被索引的唯一版本。此外,sitemap.xml文件的缺失、未提交或包含错误URL,也会影响搜索引擎发现和收录页面的效率。
2. 内容与质量问题:审视页面价值
如果技术设置无误,问题可能出在页面内容本身。搜索引擎倾向于索引能为用户提供独特价值的页面。
核心问题是 内容质量过低。一个页面如果内容稀少、信息陈旧、由程序自动生成或仅仅是图片/视频的集合而没有足够的文字描述,就可能被认为是“Thin Content”(内容贫乏)。搜索引擎会主动过滤掉这类低价值页面,不予索引。确保您的内容原创、详尽,能真正满足用户的搜索意图。
其次,注意 重复内容。当网站内部存在大量高度相似的页面(例如,仅参数不同的URL、打印版页面、HTTP/HTTPS或WWW/非WWW版本未做统一),搜索引擎会选择其中一个作为代表,其他版本则可能被排除在索引之外。使用工具如Screaming Frog可以批量爬取网站,轻松发现重复内容问题。
最后,警惕 关键词堆砌与不自然语言。为过度追求关键词密度而生硬地在文中堆砌词语,会导致文本可读性极差。这种行为是明显的SEO作弊信号,极易触发搜索引擎的垃圾内容过滤器,使页面被降权或拒绝索引。内容创作应始终以自然流畅、用户友好为第一原则。
3. 高级排查:审视外部因素与工具运用
在排除了上述基础问题后,若仍未解决,需从更宏观的角度进行诊断。
网站权重与历史 是一个不可忽视的因素。一个全新的域名或历史记录不佳、几乎没有外部信任投票(即反向链接)的网站,其爬行和索引优先级会很低。搜索引擎会投入较少资源来抓取这类网站,导致新页面收录缓慢。此时,除了持续产出高质量内容并建立健康的内外链结构外,没有捷径。
务必检查是否存在 算法惩罚或手动操作。在GSC的“安全性”和“手动操作”报告中,任何来自搜索引擎的人工处罚都会明确显示,这通常是导致索引问题最严重的根源。即便没有手动处罚,网站也可能因违反算法准则(如Penguin、Panda)而被自动降低索引权重,这需要结合流量变化和外链质量进行综合判断。
利用GSC的 “网址检查”工具 是最终极的诊断手段。输入具体URL,该工具会实时报告Google看到的页面状态,包括“是否已编入索引”、“覆盖范围”以及具体的错误原因(例如,“因发现重复内容而未选择规范页面”、“被 robots.txt 屏蔽”等)。根据工具提供的具体原因进行针对性修复,修复后使用该工具的“请求编入索引”功能,可以主动通知Google重新抓取和评估页面,加速问题解决进程。
六、实战指南:如何修复未索引的关键词
关键词未被索引,意味着Google已发现你的页面与该查询相关,但认为其质量或相关性不足,无法进入排名池。这通常是内容与技术的双重警报。以下是系统性的修复流程,旨在精准定位问题并高效解决。

1. 第一步:精准诊断未索引根源
修复始于诊断。错误的诊断将导致无效的精力投入。首先,登录Google Search Console,进入“效果”报告,筛选出你关注的关键词。接着,添加“页面”维度,并查看这些页面的“索引状态”。确定为“未索引:已抓取,尚未编入索引”后,从以下三个核心维度深挖原因:
- 内容质量评估:页面是否提供独特、全面且超越搜索结果前五名的价值?内容是否单薄、存在事实错误或仅仅是信息的简单堆砌?谷歌的核心是满足用户需求,低质内容是首个被剔除的对象。
- 搜索意图匹配度:分析目标关键词的SERP(搜索引擎结果页)特征。排名靠前的都是什么类型的内容?是操作指南、产品对比、新闻资讯还是定义解释?你的页面内容形式与用户的核心意图是否一致?意图错位是导致页面无法获得排名的关键原因。
- 技术性障碍排查:使用URL检查工具对页面进行实时检测。确认是否存在覆盖整个页面的
noindex标签、robots.txt文件是否意外屏蔽了该URL或其重要资源(如CSS、JS)、页面是否存在严重的加载速度问题或移动端兼容性错误。这些技术硬伤会直接阻止索引。
2. 第二步:执行针对性内容与技术优化
在明确病因后,需立即动手修复。此步骤的核心是“对症下药”,从内容和技术两个层面同时发力。
-
内容重塑与深度强化:如果问题是内容质量或意图不符,必须对页面进行实质性改造。参照SERP的成功范例,补充缺失的核心章节(如常见问题、案例研究、数据图表),增加独特的专家见解或实操细节,确保内容不仅全面,而且具有不可替代的深度。同时,重写标题标签和Meta描述,使其更精准地匹配关键词意图,提升点击潜力。
-
清除技术壁垒并传递权重:针对技术问题,立即移除错误的
noindex指令,修正robots.txt规则。优化页面加载速度,压缩图片、利用浏览器缓存。更重要的是,建立强大的内部链接网络:从网站内与该主题高度相关且权重较高的页面,使用包含目标关键词的精准锚文本,链接至这个未索引的页面。这能帮助Google爬虫重新发现该页面,并有效传递权重与主题相关性,是推动页面从“已抓取”迈向“已编入索引”的关键催化剂。完成优化后,可在URL检查工具中请求重新编入索引,加速Google的重新评估过程。
七、建立索引检查的常规工作流:频率与最佳时机
索引维护是保障数据库性能的核心环节,但绝非一次性的任务。一个高效的索引检查工作流,必须精准定义其执行频率与最佳时机,从而在性能收益与系统开销之间取得最佳平衡。这需要结合业务特性、数据变更模式及系统负载进行综合规划。

1. 确定检查频率:从业务周期到系统负载
索引检查频率并非一成不变,而应是一个动态调整的策略。其核心依据是业务数据的“活性”与系统负载的“潮汐”规律。
首先,紧密对齐业务周期。对于具有明显业务峰值的系统,如电商平台的“双十一”、SaaS产品的月末结算周期,必须在高峰来临前增加检查频率,例如从每月一次提升至每周一次,确保核心查询索引在流量洪峰冲击下保持最优状态。反之,在业务平稳期,可适当降低频率,减少不必要的资源消耗。
其次,评估数据变更速率(DML操作频率)。高频的INSERT、UPDATE、DELETE操作是导致索引碎片和统计信息过时的根源。一个高并发的交易系统,其索引可能每天都会产生显著碎片,需要每日或每两日进行一次例行检查。而对于数据变更稀少、以查询为主的数据仓库或历史归档库,检查频率可放宽至每月甚至每季度一次。
最后,建立基于性能指标的触发机制。通过持续监控关键指标来动态调整频率。设定硬性阈值,例如:当索引平均碎片率超过15%时,触发一次深度检查;当核心查询的平均执行时间环比增长超过20%时,立即启动诊断流程。这种响应式策略能确保问题在萌芽阶段即被发现和处理,避免性能劣化。
2. 选择最佳时机:规避高峰,利用低谷
执行索引检查或重建操作本身消耗大量I/O和CPU资源,若时机不当,极易对线上业务造成冲击。因此,选择最佳执行窗口至关重要。
第一,精准识别系统低谷时段。通过分析历史监控数据,描绘出CPU使用率、I/O吞吐、网络流量及活跃连接数的变化曲线,找出系统负载最低的稳定时段。这通常是深夜、凌晨或周末。对于全球化业务,需根据不同时区的用户活跃度,分区域规划维护窗口。
第二,避开关键业务的批量处理窗口。许多系统在夜间运行数据抽取、报表生成、账务清算等批量任务。必须与业务方协同,获取所有关键任务的执行计划,确保索引维护窗口与这些任务完全错开,避免资源争抢导致两者双双延迟甚至失败。
第三,合理运用在线操作选项。现代数据库系统普遍提供在线索引重建功能。虽然其资源消耗和执行时间通常大于离线操作,但它能最大限度减少对业务查询的锁定和阻塞。对于7x24小时不间断服务的核心系统,牺牲部分维护效率,采用在线模式是保障业务连续性的必要选择。
3. 构建自动化工作流:将策略固化为实践
将上述频率与时机的策略转化为可执行、可监控的自动化流程,是实现高效索引管理的终极步骤。
首先,编写标准化脚本。脚本应包含自动检测逻辑:遍历数据库中的关键表与索引,根据预设的碎片率阈值(如>30%执行REBUILD,10%-30%执行REORGANIZE)自动选择最优维护操作,并在操作完成后自动更新统计信息。
其次,集成调度系统。利用数据库自带的作业调度器(如SQL Server Agent)、操作系统定时任务或更专业的调度平台(如Airflow),将脚本固化。根据第一节的频率策略和第二节的时机策略,设定精确的执行计划(Cron表达式),实现无人值守的周期性执行。
最后,建立完善的日志与告警机制。每次作业执行的结果、耗时、及发现的严重问题都必须被详细记录。当作业执行失败、或发现索引碎片率异常飙升时,应立即通过邮件、短信或即时通讯工具向DBA团队发送告警,确保问题能被快速响应和处理,形成策略-执行-反馈的闭环管理。
八、超越基础检查:Index Checker 与其他 H10 工具的联动
Index Checker 的功能远不止简单的“是”或“否”验证。在 Helium 10 的生态系统中,它是连接关键词发现、Listing优化和排名增长的关键枢纽。将其孤立使用,仅能解决“我的词是否被收录”的单一问题;但若与其他核心工具联动,便能构建起一套从策略到执行、从监控到迭代的完整工作流,真正实现数据驱动的精细化运营。
1. 关键词研究的闭环:从 Magnet/Cerebro 到 Index Checker
任何成功的亚马逊运营都始于精准的关键词研究。使用 Magnet 和 Cerebro,我们能挖掘出具有高搜索量、高转化潜力的目标词库。然而,将这些关键词填入 Listing 只是第一步,真正的闭环在于验证。
工作流的关键在于“验证”环节。当通过 Magnet/Cerebro 确定一个核心关键词(例如 "large capacity travel backpack")后,立即使用 Index Checker 输入 ASIN + 关键词 进行查询。如果结果显示已收录,这意味着你的产品在该关键词下具备了自然排名的起点,可以利用 Keyword Tracker 开始追踪初始排名。如果结果显示未收录,这并非失败,而是一个明确的行动指令:你必须优先处理这个关键词。这通常意味着需要将该词更显著地植入标题或五点描述中,或启动精准 PPC 广告活动来“强制”收录。这个从“发现”到“验证”的即时反馈,避免了无效的关键词堆砌,确保了后续所有优化工作都建立在“可见”的基础之上。
2. Listing优化的动态监控:Frankenstein/Scribbles 与 Index Checker 的协同
Listing 优化是一个持续迭代的过程,而非一次性任务。当你利用 Frankenstein 整理和优化后台关键词,或使用 Scribbles 将新词组有机地植入标题、五点描述和 A+页面时,Index Checker 扮演着“效果检测器”的角色。
假设你完成了一次全面的 Listing 更新,替换了部分长尾词。在亚马逊系统更新(通常为24-48小时)后,批量使用 Index Checker 检查所有新植入的关键词。这个动作能迅速揭示优化的有效性。如果一个高期望的关键词依然显示未收录,这便是一个强烈的信号,提示你可能存在关键词稀释、植入位置不佳或与产品相关性不足等问题。反之,若大部分新词被成功收录,则证明优化方向正确。这种“优化-验证-再优化”的动态循环,将 Listing 优化从凭感觉的“艺术”转变为一门有数据支撑的“科学”,极大提升了优化的精准度和效率。
3. 驱动排名的引擎:结合 PPC 和 Index Checker 的增长策略
PPC 广告不仅是引流和出单的工具,更是推动关键词自然排名的核心引擎。Index Checker 在此策略中,扮演着衡量广告真实效益的“标尺”。
当一个重要的关键词自然未收录时,最直接有效的方法是为其创建一个精准匹配的 PPC 广告活动。此时,Index Checker 的监控频率应提高至每日。一旦检测到该词从“未收录”变为“已收录”,就意味着你成功撬动了亚马逊的自然排名算法,广告的首要目标已经达成。接下来,持续的广告投入将逐步提升其自然排名。此外,Index Checker 还能验证 PPC 广告的健康度。如果某个关键词的 PPC 广告花费很高,订单也不错,但 Index Checker 显示其长期未收录或自然排名停滞不前,这往往意味着 Listing 本身(如评论、图片、转化率)存在硬伤,无法承接广告带来的流量。这促使你审视并优化 Listing 的整体质量,而不是盲目增加广告预算,从而实现对 PPC 真实 ROI 的全面评估。

九、关于索引的常见误区与高级技巧
索引是提升数据库查询性能的核心工具,但对其错误的理解和滥用往往适得其反。本章节将剖析常见认知误区,并介绍进阶高效技巧。
1. 误区一:索引越多越好
这是最普遍的误解。认为为所有可能的查询字段都建立索引就能保障性能,实则不然。首先,增加索引意味着每次INSERT、UPDATE、DELETE操作都需要同步更新索引结构,显著增加写操作的耗时与I/O负担。其次,每个索引都是独立的物理存储结构,会占用额外的磁盘空间,在数据量巨大的表中,这部分开销不容忽视。最后,过多的索引可能让查询优化器陷入“选择困难”,反而选择了非最优的执行计划,导致性能下降。索引的建立应遵循“按需创建”原则,精准定位高频、慢查询场景,权衡读写性能。
2. 误区二:索引对所有查询都有效
并非所有设置了索引的查询都能享受到性能提升。当查询语句对索引列施加不友好操作时,索引会“失效”。典型场景包括:一、在索引列上使用函数或计算,如WHERE YEAR(create_time)=2023,数据库无法利用索引的有序性进行查找,必须进行全表扫描。正确做法是改写为范围查询,如create_time >= '2023-01-01' AND create_time < '2024-01-01'。二、查询条件与索引列类型不匹配(如字符串类型的索引列用数字查询),会引发隐式类型转换,导致索引失效。三、以通配符开头的LIKE查询(如LIKE '%keyword')无法利用B-Tree索引,同样会导致全表扫描。编写SQL时必须确保查询对索引是“友好”的,才能发挥其最大价值。
3. 高级技巧:善用覆盖索引与索引下推
深刻理解并利用数据库的内部优化机制,是性能调优的进阶之道。覆盖索引与索引下推是其中两大利器。
覆盖索引是指如果一个索引包含了查询所需的所有字段(SELECT列表、WHERE条件、ORDER BY字段),数据库只需扫描索引即可返回结果,完全无需回表查询数据行。这极大地减少了I/O操作。例如,对于SELECT user_id, user_name FROM users WHERE status = 1,建立(status, user_id, user_name)的联合索引即可实现覆盖,查询效率将得到质的飞跃。
索引下推(Index Condition Pushdown, ICP)则是将WHERE条件中可以用索引进行部分过滤的操作,“下推”到存储引擎层执行。在联合索引的查询中效果尤为显著。例如,对于(a, b)联合索引的查询WHERE a > 10 AND b = 'x',没有ICP时,数据库会先通过索引找出所有a > 10的主键,然后回表取出完整行,再过滤b = 'x'。启用ICP后,存储引擎在扫描索引时就会同时检查b = 'x'条件,仅将满足条件的记录返回给上层服务器,大幅减少了回表次数和CPU开销。
- 我的微信
- 这是我的微信扫一扫
-

- 我的微信公众号
- 我的微信公众号扫一扫
-






